#0.引言
MyBatis 是轻量级的 Java 持久层中间件,完全基于 JDBC 实现持久化的数据访问,支持以 xml 和注解的形式进行配置,能灵活、简单地进行 SQL 映射,也提供了比 JDBC 更丰富的结果集,应用程序可以从中选择对自己的数据更友好的结果集。本文将从一个简单的快速案例出发,为读者剖析 MyBatis 的整体架构与运行流程。本次分析中涉及到的代码和数据库表可以从 GitHub 上下载:mybatis-demo 。
话不多说,现在开始🔛🔛🔛!
#1.一个简单的 MyBatis 快速案例
MyBatis官网 给出了一个 MyBatis 快速入门案例,简单概括下来就是如下步骤:
- 创建 Maven 项目并在 pom.xml 文件中引入 MyBatis 的依赖;
- 准备数据库连接配置文件(database.properties)及 MyBatis 配置文件(mybatis-config.xml);
- 准备数据库表单对应的实体类(Entity)以及持久层接口(Mapper/Dao);
- 编写持久层接口的映射文件(Mapper/Dao.xml);
- 编写测试类。
创建学生表用于测试:
CREATE TABLE `student` (
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT '学生ID',
`name` varchar(20) DEFAULT NULL COMMENT '姓名',
`sex` varchar(20) DEFAULT NULL COMMENT '性别',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
该表单对应的实体类以及包括增删改查方法的持久层接口可在 entity 包和 mapper 包查看,数据库连接和 MyBatis 的配置文件以及持久层接口的映射文件可以在 resource 包下查看。
测试类如下:
public class StudentTest {
private InputStream in;
private SqlSession sqlSession;
@Before
public void init() throws IOException {
// 读取MyBatis的配置文件
in = Resources.getResourceAsStream("mybatis-config.xml");
// 创建SqlSessionFactory的构建者对象
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
// 使用builder创建SqlSessionFactory对象
SqlSessionFactory factory = builder.build(in);
// 使用factory创建sqlSession对象并设置自动提交事务
sqlSession = factory.openSession(true);
}
@Test
public void test() {
// 使用sqlSession创建StudentMapper接口的代理对象
StudentMapper studentMapper = sqlSession.getMapper(StudentMapper.class);
// 使用代理对象执行相关方法
System.out.println(studentMapper.getStudentById(2));
studentMapper.updateStudentName("托尼·李四", 2);
System.out.println(studentMapper.getStudentById(2));
System.out.println(studentMapper.findAll());
}
@After
public void close() throws IOException {
// 关闭资源
sqlSession.close();
in.close();
}
}
测试类运行结果如下:
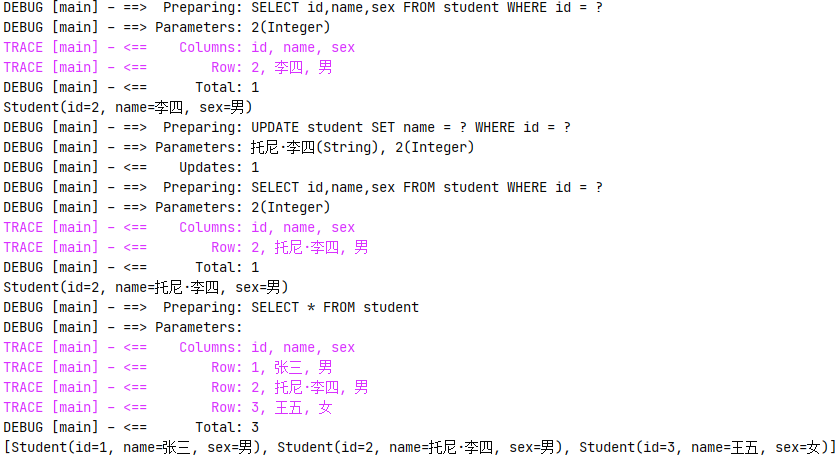
可以看到测试类成功执行了相应方法,这样就完成了 MyBatis 的快速案例实现。要注意的是,在上面的案例中我们采用的是为持久层接口编写相应 xml 映射文件的方法,其部分配置如下所示:
<select id="getStudentById" parameterType="int" resultType="com.chiaki.entity.Student">
SELECT id,name,sex FROM student WHERE id = #{id}
</select>
此外,在 MyBatis 中还提供了基于 Java 注解的方式,即在持久层接口的方法前使用对应的注解,如下所示:
@Select("SELECT id,name,sex FROM student WHERE id = #{id}")
Student getStudentById(int id);
两种方法各有优劣。基于注解的方法减少了配置文件,使代码更加简洁,但是在面对复杂 SQL 时候会显得力不从心;基于配置文件的方法虽然需要编写配置文件,但其处理复杂 SQL 语句的能力更强,实现了 Java 代码与 SQL 语句的分离,更容易维护。在笔者看来, Mapper.xml 配置文件就像是 MyBatis 的灵魂,少了它就没那味儿了,😄😄😄。不过到底采用哪种方式来配置映射,读者可以根据实际业务来灵活选择。
当然上述关于 MyBatis 的使用方式都离不开通过代码手动注入配置,包括创建 SqlSessionFactory、SqlSession等对象的步骤。此外,也可以采用将 MyBatis 与 Spring 等容器集成的方式来进行使用,这也是目前非常受欢迎的方式,由于本文主要是介绍 MyBatis 的偏底层的原理,因此这里不做详细介绍。
#2. MyBatis 的整体架构
在上一小节中我们进行了 MyBatis 的快速实现,也看到了 Resources 、 SqlSessionFactory 以及 SqlSession 等 MyBatis 框架中的一些类,那么 MyBatis 的系统架构到底是什么样的呢?我们通过结合 MyBatis 的源码项目结构得到下面的 MyBatis 整体框架图:
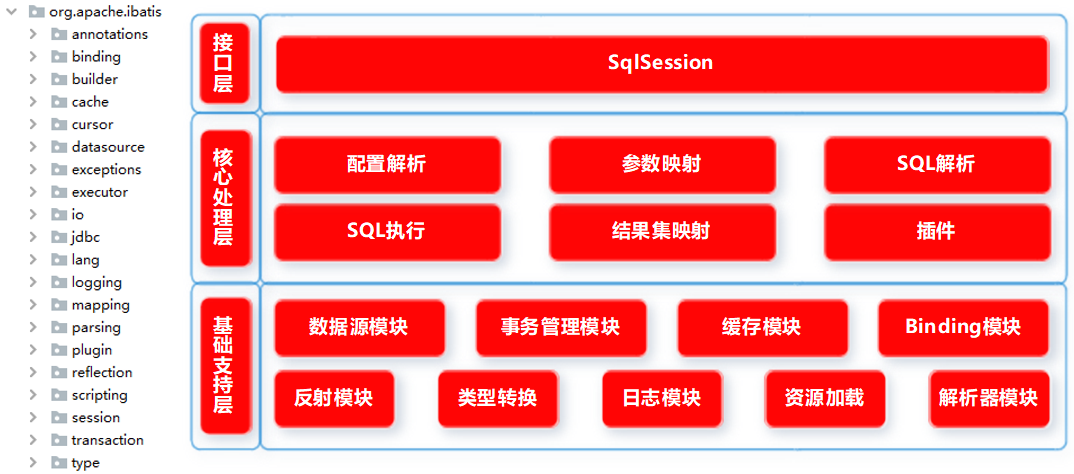
可以看出,在 MyBatis 源码中基本上是每一个 package 对应一个模块,模块之间互相配合确保 MyBatis 的成功运行。下面分层介绍 MyBatis 的整体架构。
#2.1 基础支持层
| 模块名称 | 关联package | 作用 |
|---|---|---|
| 数据源模块 | datasource | 数据源及数据工厂的代码。 |
| 事务管理模块 | transaction | 事务支持代码。 |
| 缓存模块 | cache | 缓存实现代码。 MyBatis 提供以及缓存与二级缓存。 |
| Binding模块 | binding | 映射绑定。将用户自定义的 Mapper 接口与映射配置文件关联。 |
| 反射模块 | reflection | 反射是框架的灵魂。 MyBatis 对原生的反射进行了良好的封装,实现了更简洁的调用。 |
| 类型转换 | type | 类型处理。包含了类型处理器接口 TypeHandler 、父类 BaseTypeHandler 以及若干子类。 |
| 日志模块 | logging | 提供日志输出信息,并且能够集成 log4j 等第三方日志框架。 |
| 资源加载 | io | 对类加载器进行封装,确定类加载器的使用顺序,并提供加载资源文件的功能。 |
| 解析器模块 | parsing | 一是对 XPath 进行封装,二是为处理动态 SQL 中的占位符提供支持。 |
#2.2 核心处理层
| 模块名称 | 关联package | 作用 |
|---|---|---|
| 配置解析 | builder | 解析 Mybatis 的配置文件和映射文件,包括 xml 和 annotation 两种形式的配置。 |
| 参数映射 | mapping | 主要是 ParameterMap ,支持对输入参数的判断、组装等。 |
| SQL解析 | scripting | 根据传入参数解析映射文件中定义的动态 SQL 节点,处理占位符并绑定传入参数形成可执行的 SQL 语句。 |
| SQL执行 | executor | 在 SQL 解析完成之后执行SQL语句德奥结果并返回。 |
| 结果集映射 | mapping | 主要是 ResultMap ,与 ParameterMap 类似。 |
| 插件 | plugin | 可以通过添加自定义插件的方式对 MyBatis 进行扩展。 |
#2.3 接口层
接口层对应的 package 主要是 session ,其中的核心是 SqlSession 接口,该接口定义了 MyBatis 暴露给用户调用的一些 API ,包括了 Select() 、 update() 、 insert() 、 delete() 等方法。当接口层收到调用请求时就会调用核心处理层的模块来完成具体的数据库操作。
#3. MyBatis的运行流程
#3.1 MyBatis 运行流程结构
本节中首先结合快速入门案例与 MyBatis 的整体架构来梳理其运行流程结构,如下图所示:
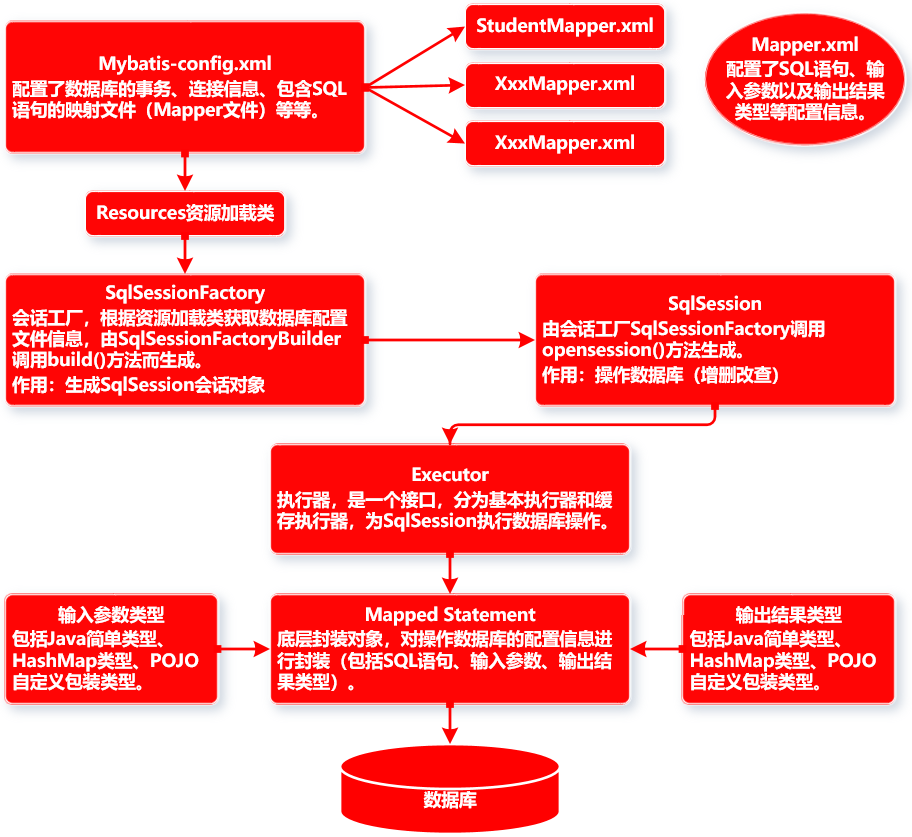
可以说, MyBatis 的整个运行流程结构,紧紧围绕着配置文件 MyBatis-config.xml 与 SQL 映射文件 Mapper.xml 文件展开。首先 SqlSessionFactory 会话工厂会通过 io 包下的 Resources 资源信息加载对象获取 MyBatis-config.xml 配置文件信息,然后产生可以与数据库进行交互的 SqlSession 会话实例类。会话实例 SqlSession 可以根据 Mapper.xml 配置文件中的 SQL 配置,去执行相应的增删改查操作。而在 SqlSession 类中,是通过执行器 Executor 对数据库进行操作。执行器与数据库交互依靠的是底层封装对象 Mapped Statement ,其封装了从 Mapper 文件中读取的包括 SQL 语句、输入参数类型、输出结果类型的信息。通过执行器 Executor 与 Mapped Statement 的结合, MyBatis 就实现了与数据库进行交互的功能。
#3.2 一条 SQL 语句的执行过程分析
本小节以一条具体的 SQL 语句为例,来分析 MyBatis 的执行过程,测试方法如下所示,其对应的语句是根据主键 ID 查询学生信息,测试方法运行前后的执行动作参见第 1 小节中 @Before 与 @After 注解下的方法,此处省略。
@Test
public void testSqlExecute() {
StudentMapper studentMapper = sqlSession.getMapper(StudentMapper.class);
Student student = studentMapper.getStudentById(2);
System.out.println(student);
}
#3.2.1 配置文件转换成输入流
首先,通过 io 包下的 Resources 类加载配置文件,将 Mapper .xml 文件转换为输入流,具体源码可以参考 org.apache.ibatis.session.io.Resources 类,如下所示。同时在 Resources 类中, MyBatis 还提供了其它的一些文件读取方法,方便用户使用。
public static InputStream getResourceAsStream(ClassLoader loader, String resource)throws IOException {
InputStream in = classLoaderWrapper.getResourceAsStream(resource, loader);
if (in == null) {
throw new IOException("Could not find resource " + resource);
}
return in;
}
#3.2.2 创建会话工厂 SqlSessionFactory
在得到配置文件的输入流之后, MyBatis 会调用 org.apache.ibatis.session.SqlSessionFactory 类中的 build() 方法创建 SqlSessionFactory 会话工厂。通过查看源码可以发现在 SqlSessionFactory 类中重载了很多 build() 方法,这里主要介绍下面三个方法:
// 方法一
public SqlSessionFactory build(InputStream inputStream) {
return build(inputStream, null, null);
}
// 方法二
public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) {
try {
// 创建XMLConfigBuilder类型的对象用于解析配置文件
XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);
// 调用parse()方法生成Configuration对象并调用build()方法返回SqlSessionFactory对象
return build(parser.parse());
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error building SqlSession.", e);
} finally {
ErrorContext.instance().reset();
try {
inputStream.close();
} catch (IOException e) {
// Intentionally ignore. Prefer previous error.
}
}
}
// 方法三
public SqlSessionFactory build(Configuration config) {
return new DefaultSqlSessionFactory(config);
}
从案例中我们看到在创建会话工厂时调用方法一,即 build(InputStream inputStream) 方法,在该方法中其实调用了方法二,只不过将 environment 和 propertoes 参数置为 null 。我们重点看方法二,该方法中涉及到 org.apache.ibatis.builder.xml 包的 XMLConfigBuilder 类,该类继承自 BaseBuilder 类,并初始化了一个用于解析配置文件的对象 parser , 然后在 return 语句中调用的是方法三,看到这里我们肯定发现方法三中 build() 方法的参数 parser.parse() 肯定是 Configuration 类型。在创建会话工厂的步骤中, Configuration 的解析过程是一个关键的流程,下面我们会逆向探究 Configuration 的详细解析过程。
- 3.2.2.1 XMLConfigBuilder#parse()
先看看这个 XMLConfigBuilder 类型的 parser 对象下的 parse() 方法,探究这个方法是如何生成 Configuration 类型的对象的。 parse() 方法定义在 org.apache.ibatis.session.builder.XMLConfigBuilder 类中,该方法的源代码以及相应注释如下所示,可以看出真正重要的是 parseConfiguration() 方法。
public Configuration parse() {
if (parsed) {
throw new BuilderException("Each XMLConfigBuilder can only be used once.");
}
parsed = true;
// 先调用parser的evalNode()方法获取 "/configuration"下的节点
// 然后调用parseConfiguration()方法解析节点的信息并返回Configuration对象
parseConfiguration(parser.evalNode("/configuration"));
return configuration;
}
- 3.2.2.2 XMLConfigBuilder#parseConfiguration()
直接查看 XMLConfigBuilder#parseConfiguration() 方法的源码如下所示:
// 解析配置文件的各个节点并将其设置到configuration对象
private void parseConfiguration(XNode root) {
try {
// 1.处理properties节点
propertiesElement(root.evalNode("properties"));
// 2.处理settings节点
Properties settings = settingsAsProperties(root.evalNode("settings"));
// 3.加载自定义的VFS设置
loadCustomVfs(settings);
// 4.加载自定义的日志实现设置
loadCustomLogImpl(settings);
// 5.处理typeAliases节点
typeAliasesElement(root.evalNode("typeAliases"));
// 6.处理plugins节点
pluginElement(root.evalNode("plugins"));
// 7.处理objectFactory节点
objectFactoryElement(root.evalNode("objectFactory"));
// 8.处理objectWrapperFactory节点
objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));
// 9.处理reflectorFactory节点
reflectorFactoryElement(root.evalNode("reflectorFactory"));
// 10.处理settings节点
settingsElement(settings);
// 11.处理environments节点
environmentsElement(root.evalNode("environments"));
// 12.处理databaseIdProvider节点
databaseIdProviderElement(root.evalNode("databaseIdProvider"));
// 13.处理typeHandlers节点
typeHandlerElement(root.evalNode("typeHandlers"));
// 14.处理mappers节点
mapperElement(root.evalNode("mappers"));
} catch (Exception e) {
throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
}
}
要注意的是 parseConfiguration() 方法在处理配置文件的节点后会把相应配置写入到该类的成员变量 configuration 中然后返回。我们以处理 mappers 节点的 mapperElement() 方法为例来进行说明,对其它主配置文件节点的解析方法读者可以自行参照源码阅读和理解。
- 3.2.2.3 XMLConfigBuilder#mapperElement()
在 mappers 节点下主要是 mapper 的配置方式,是 MyBatis 中重要的一部分。首先要明确在 MyBatis 配置文件的 mappers 节点下配置 mapper 的四种方式:
<mappers>
<!-- 1.使用相对于类路径的资源引用 -->
<mapper resource="mapper/StudentMapper.xml"/>
<!-- 2.使用完全限定资源定位符(URL) -->
<mapper url="file:src/main/resources/mapper/StudentMapper.xml"/>
<!-- 3.使用映射器接口实现类的完全限定类名-->
<mapper class="com.chiaki.mapper.StudentMapper"/>
<!-- 4.使用包内的映射器接口实现全部注册为映射器 -->
<package name="com.chiaki.mapper"/>
</mappers>
下面我们通过 MyBatis 的源码来看看 mappers 节点是如何被解析的,在 XMLConfigBuilder 类中找到 mapperElement() 方法,如下所示:
private void mapperElement(XNode parent) throws Exception {
if (parent != null) {
// 遍历子节点
for (XNode child : parent.getChildren()) {
// 子节点是package,也就是上面配置mapper的第四种方式
if ("package".equals(child.getName())) {
// 获取package的路径
String mapperPackage = child.getStringAttribute("name");
// 向Configuration的类成员遍历MapperRegistry添加mapper接口
// addMappers()方法位于Configuration类中
configuration.addMappers(mapperPackage);
} else {
// 永远先执行else语句,因为dtd文件声明mappers节点下mapper子节点必须在package子节点前面
// 获取mapper节点中的resource、url以及class属性
String resource = child.getStringAttribute("resource");
String url = child.getStringAttribute("url");
String mapperClass = child.getStringAttribute("class");
// 只有resource属性,也就是上面配置mapper的第一种方式
if (resource != null && url == null && mapperClass == null) {
ErrorContext.instance().resource(resource);
try(InputStream inputStream = Resources.getResourceAsStream(resource)) {
// 生成XMLMapperBuilder类型的mapperParser对象,即mapper解析器
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments());
// 调用解析器的parse方法进行解析
mapperParser.parse();
}
} else if (resource == null && url != null && mapperClass == null) {
ErrorContext.instance().resource(url);
try(InputStream inputStream = Resources.getUrlAsStream(url)){
// 只有url属性,也就是上面配置mapper的第二种方式
// 仍然是生成XMLMapperBuilder类型的mapper解析器
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, url, configuration.getSqlFragments());
// 调用parse()方法
mapperParser.parse();
}
} else if (resource == null && url == null && mapperClass != null) {
// 只有class属性,也就是上面配置的第三种方式
// 通过反射获取mapper接口类
Class<?> mapperInterface = Resources.classForName(mapperClass);
// 调用addMapper()方法
configuration.addMapper(mapperInterface);
} else {
throw new BuilderException("A mapper element may only specify a url, resource or class, but not more than one.");
}
}
}
}
}
这段代码中对应着 mappers 节点配置的四种情况:
- 节点名为 mapper 时分三种情况:
- resource 不为空时从 classpath 加载 xml 文件(方式一);
- url 不为空时从 URL 加载 xml 文件(方式二);
- mapperClass不为空时扫描 mapper 接口和接口上的注解,调用 addMapper() 方法(方式三)。
- 节点名为 package ,扫描该包下所有 mapper 接口和注解,调用 addMappers() 方法(方法四)。
方式一和方式二指定了 Mapper 接口与 xml 配置文件,方式三和方式四指定了 Mapper 接口。
Ⅰ. 指定 xml 文件时的 Mapper 解析与加载
(1)XMLMapperBuilder#parse()
方式一和方式二都涉及到构造 XMLMapperBuilder ,该类位于 org.apache.ibatis.builder.xml 包下,同样继承自 BaseBuilder 类。同时以上两种方式都涉及到 XMLMapperBuilder类下的一个 parse() 方法,要注意与 XMLConfigBuilder 类中的 parse() 方法进行对比区分理解。显然, XMLConfigBuilder 负责解析 MyBatis 的配置文件,而 XMLMapperBuilder 负责解析 Mapper.xml 文件。找到 XMLMapperBuilder#parse() 方法,其源码如下:
public void parse() {
// Configuration类中定义了Set<String> loadedResources表示已加载的mapper.xml文件
// 判断是否已加载过该mapper.xml文件
if (!configuration.isResourceLoaded(resource)) {
// 解析文件中的各种配置
configurationElement(parser.evalNode("/mapper"));
// 解析完毕后将该文件添加到loadedResources中
configuration.addLoadedResource(resource);
// 为接口的全限定类名绑定相应的Mapper代理
bindMapperForNamespace();
}
// 移除Configuration中解析失败的resultMap节点
parsePendingResultMaps();
// 移除Configuration中解析失败的cache-ref节点
parsePendingCacheRefs();
// 移除Configuration中解析失败的statement
parsePendingStatements();
}
(2)XMLMapperBuilder#configurationElement()
在 parse() 方法中涉及到的 configurationElement() 方法是一个核心方法,其源码如下:
private void configurationElement(XNode context) {
try {
// 获取全限定类名
String namespace = context.getStringAttribute("namespace");
if (namespace == null || namespace.isEmpty()) {
throw new BuilderException("Mapper's namespace cannot be empty");
}
// 设置全限定类名
builderAssistant.setCurrentNamespace(namespace);
// 解析cache-ref节点
cacheRefElement(context.evalNode("cache-ref"));
// 解析cache节点
cacheElement(context.evalNode("cache"));
// 解析parameterMap
parameterMapElement(context.evalNodes("/mapper/parameterMap"));
// 解析resultMap
resultMapElements(context.evalNodes("/mapper/resultMap"));
// 解析sql节点
sqlElement(context.evalNodes("/mapper/sql"));
// 解析select|insert|update|delete节点
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
} catch (Exception e) {
throw new BuilderException("Error parsing Mapper XML. The XML location is '" + resource + "'. Cause: " + e, e);
}
}
该方法解析了 mapper 节点中所有子标签,最终通过 buildStatementFromContext() 方法解析具体 SQL 语句并生成 MappedStatement 对象。
(3)XMLMapperBuilder#buildStatementFromContext()
进一步找到 XMLMapperBuilder#buildStatementFromContext() 方法,该方法进行了重载,功能是遍历所有标签,然后创建一个 XMLStatementBuilder 类型的对象对表示实际 SQL 语句的标签进行解析,重点调用的是 parseStatementNode() 方法,源码如下所示:
private void buildStatementFromContext(List<XNode> list) {
if (configuration.getDatabaseId() != null) {
buildStatementFromContext(list, configuration.getDatabaseId());
}
buildStatementFromContext(list, null);
}
private void buildStatementFromContext(List<XNode> list, String requiredDatabaseId) {
for (XNode context : list) {
// 创建XMLStatementBuilder类型的statementParse用于对select|insert|update|delete节点进行解析
final XMLStatementBuilder statementParser = new XMLStatementBuilder(configuration, builderAssistant, context, requiredDatabaseId);
try {
// 调用parseStatementNode()方法解析
statementParser.parseStatementNode();
} catch (IncompleteElementException e) {
configuration.addIncompleteStatement(statementParser);
}
}
}
(4)XMLStatementBuilder#parseStatementNode()
找到 parseStatementNode() 方法,其位于 org.apache.ibatis.builder.xml.XMLStatementBuilder 类下,源码如下:
public void parseStatementNode() {
String id = context.getStringAttribute("id");
String databaseId = context.getStringAttribute("databaseId");
if (!databaseIdMatchesCurrent(id, databaseId, this.requiredDatabaseId)) {
return;
}
// 解析标签属性
String nodeName = context.getNode().getNodeName();
SqlCommandType sqlCommandType = SqlCommandType.valueOf(nodeName.toUpperCase(Locale.ENGLISH));
boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
boolean flushCache = context.getBooleanAttribute("flushCache", !isSelect);
boolean useCache = context.getBooleanAttribute("useCache", isSelect);
boolean resultOrdered = context.getBooleanAttribute("resultOrdered", false);
// 将include标签内容替换为sql标签定义的sql片段
XMLIncludeTransformer includeParser = new XMLIncludeTransformer(configuration, builderAssistant);
includeParser.applyIncludes(context.getNode());
// 获取Mapper返回结果类型的Class对象
String parameterType = context.getStringAttribute("parameterType");
Class<?> parameterTypeClass = resolveClass(parameterType);
// 获取LanguageDriver对象
String lang = context.getStringAttribute("lang");
LanguageDriver langDriver = getLanguageDriver(lang);
// 解析selectKey标签
processSelectKeyNodes(id, parameterTypeClass, langDriver);
// Parse the SQL (pre: <selectKey> and <include> were parsed and removed)
KeyGenerator keyGenerator;
String keyStatementId = id + SelectKeyGenerator.SELECT_KEY_SUFFIX;
keyStatementId = builderAssistant.applyCurrentNamespace(keyStatementId, true);
// 获取主键生成策略
if (configuration.hasKeyGenerator(keyStatementId)) {
keyGenerator = configuration.getKeyGenerator(keyStatementId);
} else {
keyGenerator = context.getBooleanAttribute("useGeneratedKeys",
configuration.isUseGeneratedKeys() && SqlCommandType.INSERT.equals(sqlCommandType))
? Jdbc3KeyGenerator.INSTANCE : NoKeyGenerator.INSTANCE;
}
// 通过LanguageDriver对象解析SQL内容生成SqlSource对象
SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass);
// 默认Statement的类型为PreparedStatament
StatementType statementType = StatementType.valueOf(context.getStringAttribute("statementType", StatementType.PREPARED.toString()));
// 解析并获取select|update|delete|insert标签属性
Integer fetchSize = context.getIntAttribute("fetchSize");
Integer timeout = context.getIntAttribute("timeout");
String parameterMap = context.getStringAttribute("parameterMap");
String resultType = context.getStringAttribute("resultType");
Class<?> resultTypeClass = resolveClass(resultType);
String resultMap = context.getStringAttribute("resultMap");
String resultSetType = context.getStringAttribute("resultSetType");
ResultSetType resultSetTypeEnum = resolveResultSetType(resultSetType);
if (resultSetTypeEnum == null) {
resultSetTypeEnum = configuration.getDefaultResultSetType();
}
String keyProperty = context.getStringAttribute("keyProperty");
String keyColumn = context.getStringAttribute("keyColumn");
String resultSets = context.getStringAttribute("resultSets");
// 调用addMappedStatement()将解析内容组装生成MappedStatement对象并注册到Configuration
builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType,
fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass,
resultSetTypeEnum, flushCache, useCache, resultOrdered,
keyGenerator, keyProperty, keyColumn, databaseId, langDriver, resultSets);
}
在上面的源码中会解析 select|update|delete|insert 标签的属性,然后重点是用 LanguageDriver 对象来解析 SQL 生成 SqlSource 对象。 org.apache.ibatis.scripting.LanguageDriver 类是一个接口,对应的实现类有 XMLLanguageDriver 和 RawLanguageDriver ,同时涉及到 XMLScriptBuilder 类与 SqlSourceBuilder 类等。关于 LanguageDriver 对象解析 SQL 的详细过程,读者可以循序渐进去阅读 MyBatis 的源码,这里限于篇幅就不做详细介绍了。最后会调用 org.apache.ibatis.builder.MapperBuilderAssistant#addMappedStatement() 方法将解析内容组装成 MappedStatement 对象并将其注册到 Configuration 的 mappedStatements 属性中。至此, Mapper 接口对应的 xml 文件配置就解析完成了。下面我们再回到 XMLMapperBuilder#parse() 方法看看 Mapper 是如何注册接口的。
(5)XMLMapperBuilder#bindMapperForNameSpace()
在 XMLMapperBuilder#parse() 中通过 XMLMapperBuilder#configurationElement() 方法解析完 xml 文件配置后会将其添加到已加载的资源 loadedResources 中,然后会调用 XMLMapperBuilder#bindMapperForNameSpace() 方法为接口的全限定类名绑定 Mapper 代理,即为 Mapper 接口创建对应的代理类,找到相应源码如下:
private void bindMapperForNamespace() {
String namespace = builderAssistant.getCurrentNamespace();
if (namespace != null) {
Class<?> boundType = null;
try {
boundType = Resources.classForName(namespace);
} catch (ClassNotFoundException e) {
// ignore, bound type is not required
}
if (boundType != null && !configuration.hasMapper(boundType)) {
// 调用Configuration#hasMapper()方法判断当前Mapper接口是否已经注册
configuration.addLoadedResource("namespace:" + namespace);
// 调用Configuration#addMapper()注册接口
configuration.addMapper(boundType);
}
}
}
在上面的代码中先调用 Configuration#hasMapper() 方法判断当前 Mapper 接口是否已经注册,只有没被注册过的接口会调用 Configuration#addMapper() 方法类注册接口。
(6)Configuration#addMapper()
在 Configuration 类中, 找到 addMapper() 方法发现其调用的是 MapperRegistry#addMapper() 方法。
// Configuration#addMapper()方法
public <T> void addMapper(Class<T> type) {
mapperRegistry.addMapper(type);
}
(7)MapperRegistry#addMapper()
找到 MapperRegistry#addMapper() 方法对应的源码如下:
// Configuration#addMapper()方法
public <T> void addMapper(Class<T> type) {
mapperRegistry.addMapper(type);
}
// MapperRegistry#addMapper()方法
public <T> void addMapper(Class<T> type) {
if (type.isInterface()) {
if (hasMapper(type)) {
throw new BindingException("Type " + type + " is already known to the MapperRegistry.");
}
boolean loadCompleted = false;
try {
// 调用Configuration#knownMappers属性的put方法
knownMappers.put(type, new MapperProxyFactory<>(type));
// 创建MapperAnnotationBuilder对象parser
MapperAnnotationBuilder parser = new MapperAnnotationBuilder(config, type);
// 调用MapperAnnotationBuilder#parse()方法
parser.parse();
loadCompleted = true;
} finally {
if (!loadCompleted) {
knownMappers.remove(type);
}
}
}
}
在 MapperRegistry#addMapper() 方法中,首先会调用 Configuration 类下 knownMappers 属性的 put() 方法,可以看到 key 值为 Mapper 接口对应的 Class 对象,而 value 值为 Mapper 接口对应的 Class 类型的代理工厂类 MapperProxyFactory 。这里 MapperProxyFactory 会根据 sqlSeesion 创建 Mapper 接口的一个 MapperProxy 代理实例,具体的分析我们将在后续小节解读。
(8)MapperAnnotationBuilder#parse()
在 Mapper 接口注册之后,继续往下可以看到创建了一个 MapperAnnotationBuilder 类型的对象 parser ,然后调用 MapperAnnotationBuilder#parse() 方法进行解析,我们找到 MapperAnnotationBuilder#parse() 的源码如下:
public void parse() {
String resource = type.toString();
// 判断是否被加载过
if (!configuration.isResourceLoaded(resource)) {
// 如果没有被加载则对资源进行加载
loadXmlResource();
configuration.addLoadedResource(resource);
assistant.setCurrentNamespace(type.getName());
// 解析缓存
parseCache();
parseCacheRef();
for (Method method : type.getMethods()) {
if (!canHaveStatement(method)) {
continue;
}
// 解析Mapper接口的使用SQL注解的方法,比如@Select以及@SelectProvider
if (getAnnotationWrapper(method, false, Select.class, SelectProvider.class).isPresent()
&& method.getAnnotation(ResultMap.class) == null) {
parseResultMap(method);
}
try {
// 调用parseStatement()方法
parseStatement(method);
} catch (IncompleteElementException e) {
configuration.addIncompleteMethod(new MethodResolver(this, method));
}
}
}
parsePendingMethods();
}
通过阅读源码可以知道 MapperAnnotationBuilder#parse() 方法会对接口上的 SQL 注解进行解析,解析完成后生成对应的 MappedStatement 对象并注册到 Configuration 的 mappedStatements 属性中,这里在后面展开详细解析。
(9) 小结
至此我们已经梳理清楚了在指定 xml 文件时 Mapper 的解析与加载流程。回过头看,我们从 XMLMapperBuilder#parse() 方法开始层层递进,犹如抽丝剥茧一般,让人觉得酣畅淋漓,也在这里做一个小结。
- 根据 xml 文件的输入流创建 XMLMapperBuilder 对象后,调用 parse() 方法开始解析 xml 文件下 mapper 标签的信息。在阅读源码时,可以发现 XMLMapperBuilder#parse() 是一个十分重要的方法,相当于我们阅读源码的入口;
- 在 parse() 方法中又调用 XMLMapperBuilder#configurationElement() 方法解析 cache-ref 、 cache 、 parameterMap 、 resultMap 、 sql 以及 select|insert|update|delete 等标签的信息;
- 解析 select|insert|update|delete 标签时的入口方法是 XMLMapperBuilder#buildStatementFromContext() 方法,在解析时会遍历所有标签并创建对应的 XMLStatementBuilder 对象;
- 调用 XMLStatementBuilder#parseStatementNode() 方法解析 select|update|delete|insert 标签的属性,然后用 LanguageDriver 对象来解析 SQL 生成 SqlSource 对象,并调用 MapperBuilderAssistant#addMappedStatement() 方法将解析内容组装成 MappedStatement 对象并将其注册到 Configuration 的 mappedStatements 属性中;
- 回到 XMLMapperBuilder#parse() 方法,调用 Configuration#addLoadedResource() 方法将 xml 文件资源注册到 Configuration 中;
- 继续调用 XMLMapperBuilder#bindMapperForNameSpace() 方法实现当前接口的注册,方法中调用了 Configuration#addMapper() 方法,实际底层调用的是 MapperRegistry#addMapper() 方法。该方法中创建了 MapperProxyFactory 对象,负责在执行 Mapper 时根据当前 SqlSession 对象创建当前接口的 MapperProxy 代理实例;
- 最后,在 Mapper 接口注册后, MapperRegistry#addMapper() 方法中还创建了 MapperAnnotationBuilder 对象,并调用 MapperAnnotationBuilder#parse() 方法完成了对 Mapper 接口的 SQL 注解进行了解析并生成对应 MappedStatement 对象并将其注册到 Configuration 的 mappedStatements 属性中。
Ⅱ. 指定Mapper接口时Mapper的解析与加载
看完了方式一和方式二的解析与加载流程之后,我们继续回到 XMLConfigBuilder#mapperElement() 方法探究方式三和方式四中指定 Mapper 接口时的 Mapper 解析与加载流程。方式三和方式四涉及到调用 configuration 对象的 addMappers() 和 addMapper() 方法。我们找到这两个方法,发现其都位于 org.apache.ibatis.seesion 包的 Configuration 类中,其源码如下:
public <T> void addMapper(Class<T> type) {
mapperRegistry.addMapper(type);
}
public void addMappers(String packageName) {
mapperRegistry.addMappers(packageName);
}
看到这是不是觉得十分熟悉?没错,其实 addMappers() 和 addMapper() 方法的底层都是调用 MapperRegistry#addMapper() 方法实现 Mapper 接口的注册,这个方法我们已经在上文中详细介绍过了。是不是感觉少了什么流程?确实,读者可能疑惑的是:在上文中提到的指定 xml 文件时的解析和加载流程中,会先有很多解析 xml 文件的步骤然后才到 MapperRegistry#addMapper() 方法实现 Mapper 接口的注册,而在现在这种指定 Mapper 接口时的流程中一开始就调用 MapperRegistry#addMapper() 方法,那这种情况是不是就不解析 xml 了呢?说到这,就不得不提 MapperRegistry#addMapper() 方法中创建的 MapperAnnotationBuilder 对象了,上文中我们提到该对象用于解析 Mapper 接口的 SQL 注解并生成对应 MappedStatement 对象并将其注册到 Configuration 的 mappedStatements 属性中。其实方式三和方式四的重点就是对指定 Mapper 接口上的注解进行解析的,而我们知道 MyBatis 的基于注解的配置方式最大的优点就是没有 xml 配置文件,连 xml 配置文件都没有的话自然就没有 xml 文件相关的解析流程啦!不过,如果指定了 xml 文件,仍会使用 XMLMapperBuilder 来解析 xml 文件。
(1)MapperAnnotationBuilder#parse()
现在再看看 MapperAnnotationBuilder#parse() 的源码,如下所示:
public void parse() {
String resource = type.toString();
// 判断是否被加载过
if (!configuration.isResourceLoaded(resource)) {
// 如果没有被加载则对资源进行加载
loadXmlResource();
configuration.addLoadedResource(resource);
assistant.setCurrentNamespace(type.getName());
// 解析缓存
parseCache();
parseCacheRef();
for (Method method : type.getMethods()) {
if (!canHaveStatement(method)) {
continue;
}
// 解析Mapper接口的使用SQL注解的方法,比如@Select以及@SelectProvider
if (getAnnotationWrapper(method, false, Select.class, SelectProvider.class).isPresent()
&& method.getAnnotation(ResultMap.class) == null) {
parseResultMap(method);
}
try {
// 调用parseStatement()方法解析SQL注解
parseStatement(method);
} catch (IncompleteElementException e) {
configuration.addIncompleteMethod(new MethodResolver(this, method));
}
}
}
parsePendingMethods();
}
阅读源码我们发现关键的方法,即 MapperAnnotationBuilder#parseStatement() 方法,该方法是解析 SQL 注解的入口方法。
(2)MapperAnnotationBuilder#parseStatement()
在 org.apache.ibatis.builder.annotation 找到 MapperAnnotationBuilder#parseStatement() 方法的源码,如下所示:
// 四个类成员变量
// 注解对应Class对象组成的set集合
// 包括@Select、@Insert、@Update、@Delete、@SelectProvider、@InsertProvider、@UpdateProvider、@DeleteProvider注解
private static final Set<Class<? extends Annotation>> statementAnnotationTypes = Stream
.of(Select.class, Update.class, Insert.class, Delete.class, SelectProvider.class, UpdateProvider.class,
InsertProvider.class, DeleteProvider.class)
.collect(Collectors.toSet());
// 核心配置对象Configuration
private final Configuration configuration;
// Mapper构建工具
private final MapperBuilderAssistant assistant;
// 要解析的Mapper接口的Class对象
private final Class<?> type;
// parseStatement()方法,入参为Mapper中的方法
void parseStatement(Method method) {
// 获取输入参数类型的Class对象
final Class<?> parameterTypeClass = getParameterType(method);
// 获取LanguageDriver对象
final LanguageDriver languageDriver = getLanguageDriver(method);
// 流方法中的ifPresent()方法,包含lambda表达式
getAnnotationWrapper(method, true, statementAnnotationTypes).ifPresent(statementAnnotation -> {
// 获取SqlSource
final SqlSource sqlSource = buildSqlSource(statementAnnotation.getAnnotation(), parameterTypeClass, languageDriver, method);
// 通过注解获取SQL命令类型
final SqlCommandType sqlCommandType = statementAnnotation.getSqlCommandType();
// 获取方法上的@Options注解
final Options options = getAnnotationWrapper(method, false, Options.class).map(x -> (Options)x.getAnnotation()).orElse(null);
// 映射语句id设置为类的全限定名.方法名
final String mappedStatementId = type.getName() + "." + method.getName();
// 键生成器
final KeyGenerator keyGenerator;
String keyProperty = null;
String keyColumn = null;
// 如果是insert或者update,只有insert或者update才解析@SelectKey注解
if (SqlCommandType.INSERT.equals(sqlCommandType) || SqlCommandType.UPDATE.equals(sqlCommandType)) {
// 首先检查@SelectKey注解,它会覆盖其它任何配置
// 获取方法上的@SelectKey注解
SelectKey selectKey = getAnnotationWrapper(method, false, SelectKey.class).map(x -> (SelectKey)x.getAnnotation()).orElse(null);
// 如果存在@SelectKey注解
if (selectKey != null) {
keyGenerator = handleSelectKeyAnnotation(selectKey, mappedStatementId, getParameterType(method), languageDriver);
keyProperty = selectKey.keyProperty();
} else if (options == null) {
keyGenerator = configuration.isUseGeneratedKeys() ? Jdbc3KeyGenerator.INSTANCE : NoKeyGenerator.INSTANCE;
} else {
keyGenerator = options.useGeneratedKeys() ? Jdbc3KeyGenerator.INSTANCE : NoKeyGenerator.INSTANCE;
keyProperty = options.keyProperty();
keyColumn = options.keyColumn();
}
} else {
// 其它SQL命令没有键生成器
keyGenerator = NoKeyGenerator.INSTANCE;
}
Integer fetchSize = null;
Integer timeout = null;
StatementType statementType = StatementType.PREPARED;
ResultSetType resultSetType = configuration.getDefaultResultSetType();
boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
boolean flushCache = !isSelect;
boolean useCache = isSelect;
if (options != null) {
// 省略
}
String resultMapId = null;
if (isSelect) {
// 如果是查询,获取@ResultMap注解
ResultMap resultMapAnnotation = method.getAnnotation(ResultMap.class);
if (resultMapAnnotation != null) {
// @ResultMap注解不为空则解析@ResultMap注解
resultMapId = String.join(",", resultMapAnnotation.value());
} else {
resultMapId = generateResultMapName(method);
}
}
// 调用addMappedStatement()将解析内容组装生成MappedStatement对象并注册到Configuration
assistant.addMappedStatement(mappedStatementId, sqlSource, statementType, sqlCommandType, fetchSize, timeout,
null, parameterTypeClass, resultMapId, getReturnType(method), resultSetType,
flushCache, useCache, false, keyGenerator, keyProperty, keyColumn,
statementAnnotation.getDatabaseId(), languageDriver,
options != null ? nullOrEmpty(options.resultSets()) : null);});
}
通过阅读这段源码,我们发现 parseStatement() 方法中关于注解的解析过程与 XMLStatementBuilder#parseStatementNode() 方法中对 xml 文件的解析有些许相似之处。在对 xml 解析时是获取对应标签然后解析,而对注解解析时是获取方法上的注解然后进行解析,解析完成后二者都是调用 MapperBuilderAssistant#addMappedStatement() 方法组装解析内容生成 MappedStatement 对象并注册到 Configuration 中。
(3) 小结
在指定 Mapper 接口的情况下,我们分析了 Mapper 的解析与加载流程。在这种情况下主要是从 MapperAnnotationBuilder#parse() 方法入手,调用 MapperAnnotationBuilder#parseStatement() 方法对 Mapper 接口上的注解进行解析,然后将解析内容组装并生成 MappedStatement 对象并注册到 Configuration 对象的 mappedStatements 属性中。这里要注意的是,指定 Mapper 接口这种方式一般没有指定 xml 文件,这样就只会对注解进行解析,当指定 xml 文件后仍会按上小节中的步骤对 xml 文件进行解析。同理,指定 xml 文件的方式一般也没有注解,因此也只会解析 xml 文件,当存在注解时也同样会对注解进行解析。
#3.2.3 创建会话 SqlSession
在上一小节中,我们花了很大的篇幅如剥洋葱一般一层一层地理清了创建会话工厂中 Configuration 对象的解析流程,读者是否感觉对 MyBatis 的源码阅读渐入佳境了呢?下面介绍通过会话工厂 SqlSessionFactory 创建会话 SqlSession 的步骤, SqlSession 是 MyBatis 暴露给外部使用的统一接口层。
- 3.2.3.1 SqlSessionFactory#openSession()
通过案例可以看到调用 SqlSessionFactory#openSession() 方法可以创建 SqlSession 对象,找到对应源码如下:
public interface SqlSessionFactory {
SqlSession openSession();
SqlSession openSession(boolean autoCommit);
SqlSession openSession(Connection connection);
SqlSession openSession(TransactionIsolationLevel level);
SqlSession openSession(ExecutorType execType);
SqlSession openSession(ExecutorType execType, boolean autoCommit);
SqlSession openSession(ExecutorType execType, TransactionIsolationLevel level);
SqlSession openSession(ExecutorType execType, Connection connection);
Configuration getConfiguration();
}
SqlSessionFactory 是一个接口,其中重载了很多 openSession() 方法,同时还包括一个获取 Configuration 对象的 getConfiguration() 方法。
- 3.2.3.2 DefaultSqlSessionFactory#openSessionFromDataSource()
对于 SqlSessionFactory 接口,其对应的默认实现类是 org.apache.ibatis.session.defaults.DefaultSqlSessionFactory 类,在该类中找到了对应的 openSession() 方法的实现,其底层调用的是 DefaultSqlSessionFactory#openSessionFromDataSource() 方法来获取 SqlSession 对象,对应源码如下所示:
@Override
public SqlSession openSession(boolean autoCommit) {
return openSessionFromDataSource(configuration.getDefaultExecutorType(), null, autoCommit);
}
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
// jdbc事务管理器
Transaction tx = null;
try {
// 数据库环境信息
final Environment environment = configuration.getEnvironment();
// 事务工厂
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
// 通过事务工厂获取一个事务实例
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
// 获取执行器
final Executor executor = configuration.newExecutor(tx, execType);
// 获取SqlSession会话对象,其中org.apache.ibatis.session.defaults.DefaultSqlSession是SqlSession的默认实现类
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx);
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
通过下面的时序图可以更好地理解创建 SqlSession 的过程:
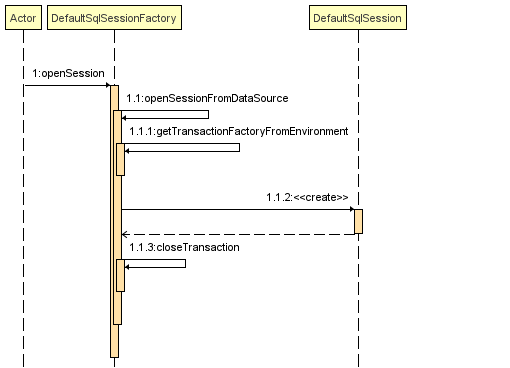
#3.2.4 创建Mapper接口的代理对象
在案例中,创建了 SqlSession 对象后会调用 getMapper() 方法创建 Mapper 接口的代理实例,下面我们先看调用该方法的时序图,如下所示:
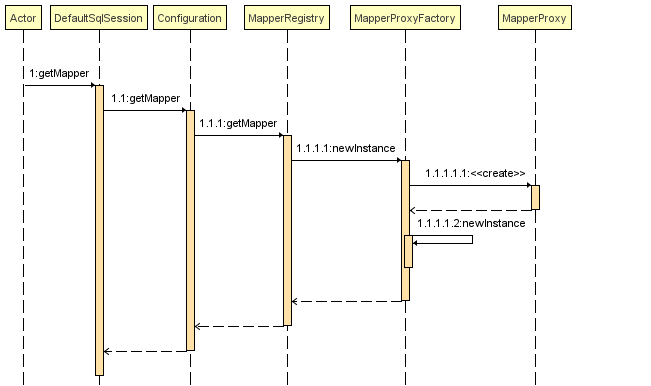
由时序图我们可以得知真正创建 MapperProxy 代理实例涉及到的核心类是 MapperProxyFactory 类和 MapperProxy 类,这两个类我们在上文中提到过,这里我们详细阅读相关源码。
- 3.2.4.1 MapperProxyFactory
在 org.apache.ibatis.binding 包找到 MapperProxyFactory 类,其源码如下所示。
public class MapperProxyFactory<T> {
// Mapper接口
private final Class<T> mapperInterface;
// Mapper接口中的方法和方法封装类的映射
private final Map<Method, MapperMethodInvoker> methodCache = new ConcurrentHashMap<>();
public MapperProxyFactory(Class<T> mapperInterface) {
this.mapperInterface = mapperInterface;
}
public Class<T> getMapperInterface() {
return mapperInterface;
}
public Map<Method, MapperMethodInvoker> getMethodCache() {
return methodCache;
}
@SuppressWarnings("unchecked")
// newInstance()方法一:代理模式,创建一个MapperProxy
protected T newInstance(MapperProxy<T> mapperProxy) {
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
}
// newInstance()方法二:根据SqlSession为Mapper接口创建一个MapperProxy代理实例
public T newInstance(SqlSession sqlSession) {
final MapperProxy<T> mapperProxy = new MapperProxy<>(sqlSession, mapperInterface, methodCache);
return newInstance(mapperProxy);
}
}
一看这个类的名字就知道这是个工厂类,目的就是为了生成 MapperProxy 。该类中由两个 newInstance() 方法,第二个 newInstance() 方法中结合通过 SqlSession 类型的参数生成了一个 MapperProxy 代理实例,然后调用第一个 newInstance() 方法返回。在第一个方法中使用 Java 的 Proxy 类生成了一个 Mapper 接口的代理类,采用的是动态代理的方式。
- 3.2.4.2 MapperProxy
紧接着找到 MapperProxy 类的部分源码如下。可以看到 MapperProxy 类实现了 InvocationHandler 接口并实现了其中的 invoke() 方法,这就是因为动态代理。
public class MapperProxy<T> implements InvocationHandler, Serializable {
private static final long serialVersionUID = -6424540398559729838L;
private final SqlSession sqlSession;
private final Class<T> mapperInterface;
private final Map<Method, MapperMethod> methodCache;
public MapperProxy(SqlSession sqlSession, Class<T> mapperInterface, Map<Method, MapperMethod> methodCache) {
this.sqlSession = sqlSession;
this.mapperInterface = mapperInterface;
this.methodCache = methodCache;
}
// 省略......
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
} else {
return cachedInvoker(method).invoke(proxy, method, args, sqlSession);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
// 省略......
}
#3.2.5 使用代理对象执行相关方法
在创建了 Mapper 接口的代理对象之后,代理对象又是怎么执行相应的方法的呢?我们在 3.2 节开头展示案例中根据ID查找学生的语句处打上断点进行调试,如图所示。

点击 step into 按钮会进入 org.apache.ibatis.binding.MapperProxy#invoke() 方法,如下图所示。
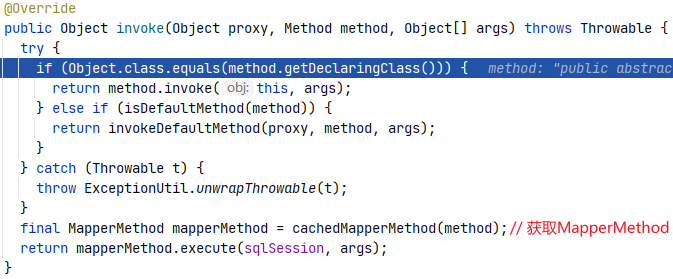
在执行 invoke() 方法后会调用 cacheMapperMethod() 方获取 MapperMethod 对象。在 MapperProxy 类中找到 cacheMapperMethod() 方法,源码如下:
private MapperMethod cachedMapperMethod(Method method) {
return methodCache.computeIfAbsent(method,
k -> new MapperMethod(mapperInterface,
method,
sqlSession.getConfiguration()));
}
在上述代码中通过 new MapperMethod() 方法创建 MapperMethod , 其中 mapperInterface 就是 com.jd.yip.mapper.StudentMapper 接口, method 就是 cacheMapperMethod() 方法传入的 Method 类型的参数,即 getStudentById() 方法,而 sqlSession.getConfiguration() 获取的就是 Configuration 配置对象。在获取到 MapperMethod 后,会执行 mapperMethod.execute(sqlSession, args) 方法返回。该方法位于 org.apache.ibatis.binding 包下的 MapperMethod 类中,源码如下所示,首先会获取 SQL 语句的类型,然后进入 switch-case 结构。
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
// 获取SQL命令类型进入switch-case
switch (command.getType()) {
case INSERT: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.insert(command.getName(), param));
break;
}
case UPDATE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.update(command.getName(), param));
break;
}
case DELETE: {
Object param = method.convertArgsToSqlCommandParam(args);
result = rowCountResult(sqlSession.delete(command.getName(), param));
break;
}
case SELECT:
if (method.returnsVoid() && method.hasResultHandler()) {
executeWithResultHandler(sqlSession, args);
result = null;
} else if (method.returnsMany()) {
result = executeForMany(sqlSession, args);
} else if (method.returnsMap()) {
result = executeForMap(sqlSession, args);
} else if (method.returnsCursor()) {
result = executeForCursor(sqlSession, args);
} else {
// 将参数转换成SQL语句的参数
Object param = method.convertArgsToSqlCommandParam(args);
// 调用SqlSession#selectOne()方法得到结果
result = sqlSession.selectOne(command.getName(), param);
if (method.returnsOptional()
&& (result == null || !method.getReturnType().equals(result.getClass()))) {
result = Optional.ofNullable(result);
}
}
break;
case FLUSH:
result = sqlSession.flushStatements();
break;
default:
throw new BindingException("Unknown execution method for: " + command.getName());
}
if (result == null && method.getReturnType().isPrimitive() && !method.returnsVoid()) {
throw new BindingException("Mapper method '" + command.getName()
+ " attempted to return null from a method with a primitive return type (" + method.getReturnType() + ").");
}
return result;
}
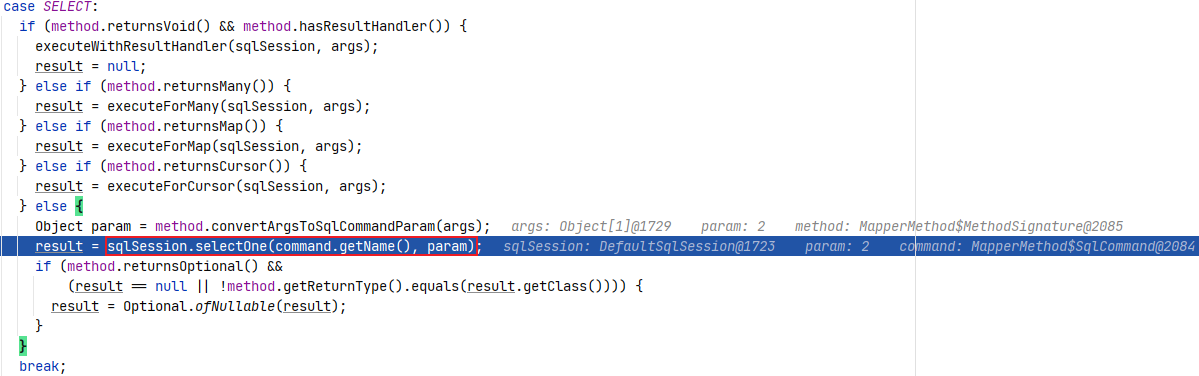
案例中根据 ID 查询学生信息属于 SELECT ,因此进入对应的 case 分支判断当前方法的返回情况,案例的情况会直接进入最后的 else 语句,先将参数转化成 SQL 语句所需参数,然后进入到 SqlSession 的默认实现类 DefaultSqlSession 中调用 selectOne() 方法,如下图所示。
进入 DefaultSqlSession#selectOne() 方法后会继续调用当前类的 selectList() 方法,如图所示。
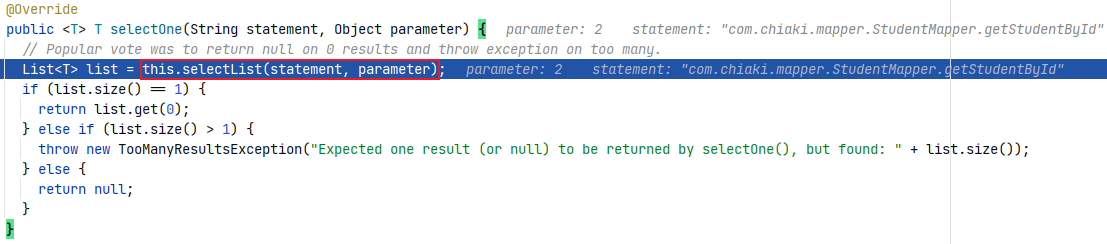
继续 step into 进入到 selectList() 方法,可以看到该方法有多种重载形式,其中最关键的是调用 Executor#query() 方法获取到查询结果。
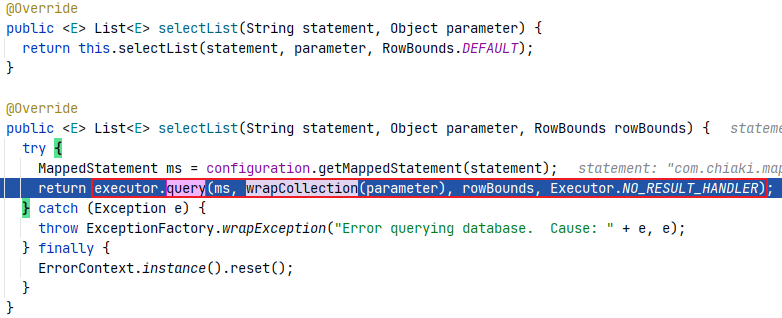
至此,我们通过调试案例代码,就理清了 Mapper 接口代理对象执行相关方法的流程,现对上述流程进行小结。
- 代理对象调用 invoke() 方法通过 cacheMapperMethod() 方法创建 MapperMethod ,然后执行 execute(sqlSession, args) 方法;
- 在 execute() 方法中根据 SQL 的类型进入相应的 case 分支;
- 在 case 分支调用 SqlSession 默认实现类 DefaultSqlSession 中与 select 、 update 、 delete 、 insert 相关的方法;
- 在 DefaultSqlSession 类中,这些与增删改查相关的方法又会调用 Executor 类中对应 query() 或 update() 等方法;
- 返回相应的结果。
#总结
本节中以根据学生 ID 查找学生信息这样一条 SQL 语句为案例,结合 MyBatis 的源码梳理了 SQL 语句的具体执行流程:
- 调用 Resources 类加载配置文件;
- 创建 SqlSessionFactory 会话工厂,这个过程中首先涉及到 XMLConfigBuilder 类解析 MyBatis 的基础配置文件,然后我们详细介绍了 XMLMapperBuilder 类与 MapperAnnotationBuilder 类实现指定 xml 文件和 指定 Mapper 接口时对 Mapper 的解析与加载,这也是本文的重点,最后 Mapper 解析加载完成后最重要的是将解析结果组装生成 MappedStatement 并注册到 Configuration 对象中;
- 根据 SqlSessionFactory 会话工厂创建 SqlSession 会话,这里涉及到 SqlSessionFactory 和 SqlSession 的默认实现类,即 DefaultSqlSessionFactory 以及 DefaultSqlSession。调用 SqlSessionFactory#openSession() 方法创建 SqlSession 的底层其实调用的是 DefaultSqlSessionFactory#openSessionFromDataSource() 方法。
- 创建 MapperProxy 代理实例,这里涉及到 MapperProxyFactory 与 MapperProxy 两个类。通过动态代理的方式,在 SqlSession 执行的时候通过 MapperProxyFactory#newInstance() 方法创建 Mapper 接口的代理对象;
- 代理对象执行相应的方法。通过断点调试的方式可以看到在执行方法时会进入代理对象的 invoke() 方法创建 MapperMethod,然后执行 execute() 方法中相应的 case 分支,随后进入 SqlSession 中执行 SQL 语句类型对应的方法,最后进入 Executor 中执行 query() 方法得到并返回结果。
#全文总结
本文从 MyBatis 的简单快速案例出发介绍了 MyBatis 的整体架构,然后介绍了 MyBatis 的运行流程结构,进一步以一条实际的 SQL 语句为案例从源码角度剖析了 SQL 语句的详细执行流程,其中重点在于 Mapper 的解析与加载以及 Mapper 接口代理对象的创建,最后对 MyBatis 的运行流程做了一定的总结。在阅读源码的过程中不难发现 MyBatis 运行时对方法的调用是一层套一层,这时候就需要读者耐心地从入口函数开始层层深入,如升级打怪一般,到最后理清整个流程后你可以获得的就是如游戏通关般的畅快感。当然,由于笔者水平有限,本文只是管中窥豹,只可见一斑而不能得全貌,读者可以跟着文章的解读思路自行探索直到窥得 MyBatis 全貌。
#参考资料
《互联网轻量级 SSM 框架解密:Spring 、 Spring MVC 、 MyBatis 源码深度剖析》
《MyBatis3 源码深度解析》
《Spring MVC + MyBatis 开发从入门到实践》